The Korean text of this paper can be translated into multiple languages on the website of http://jksee.or.kr through Google Translator.
유사하거나 동일한 폐수처리공정에서의 전이학습 적용 유무에 따른 심층학습 알고리즘의 성능 평가
Abstract
This study assessed the feasibility of transfer learning from one wastewater treatment process to another using two popular deep learning algorithms. Specifically, convolutional neural network (CNN) and long short-term memory (LSTM), which consisted of four and three hidden layers, respectively, were used as benchmark algorithms for transfer learning. Input data for both deep learning and transfer learning were provided from two wastewater treatment plants with identical treatment trains in series (located in Jinju and Cheongju City) over the five-year period from 2018 to 2022. Performance evaluation was also done not only against two deep learning algorithms but also against those adopting two transfer learning strategies, one for freezing all hidden layers developed from the pre-trained model and the other for training the last hidden layer only among multiple ones, with respect to Mean Squared Error (MSE). We found that the performance of both CNN and LSTM was relatively comparative regardless of dependent variables, discharge and biochemical oxygen demand (BOD), whereas the prediction accuracy of both algorithms was slightly higher for discharge than for BOD due to its low variability. When transfer learning which froze all hidden layers of the existing model was applied to two benchmark algorithms, the predictive performance of both algorithms was found to slightly improved only for discharge. Also, there was no measurable variation in the prediction accuracy of benchmark algorithms using the other transfer learning approach. Potential applications of transfer learning include the rapid reuse of the existing models (developed from source domains) for target domains which are hard to develop new prediction models due to the lack of data in deep learning.
Key words: Transfer learning, Deep learning, Convolutional neural network, Long short-term memory, Wastewater treatment process
요약
본 연구에서는 두 개의 인지도가 높은 심층학습 알고리즘을 사용하여 하나의 폐수처리공정에서 다른 폐수처리공정으로의 전이학습의 적용 가능성을 평가하였다. 구체적으로는, 전이학습을 위한 벤치마크 알고리즘으로4개 및 3개의 은닉층으로 각각 구성된 합성곱 신경망과 장단기 메모리를 사용하였다. 심층학습과 전이학습을 위해 (진주와 청주시에 위치한) 동일한 처리공정을 가지는 2개의 폐수처리시설로부터 2018년부터 2022년까지 총 5년간의 입력 데이터가 제공되었다. 모델의 성능 평가는 평균제곱오차를 기준으로 2개 심층학습과 더불어 2개의 다른 전이 학습 적용 방법(사전 훈련된 모델에서 개발된 모든 은닉층을 사용하는 방법과 다수의 은닉층 중 마지막 은닉층만을 훈련에 사용하는 방법)을 채택하여 수행되었다. 평가 결과, 유량 및 생물화학적 산소요구량과 같은 종속 변수에 관계없이 합성곱 신경망과 장단기 메모리의 성능은 상대적으로 유사한 것으로 조사되었으며, 다만 유량 변수의 낮은 변동성으로 인하여 생물화학적 산소요구량에 비해 유량 예측의 정확도가 다소 높은 것으로 평가되었다. 기존 모델의 모든 은닉층을 사용한 전이학습 기법을 두 가지 벤치마크 알고리즘에 적용한 결과 두 알고리즘 모두 유량에 한정하여 예측 성능이 다소 향상되는 것으로 조사되었다. 또한, 다른 전이학습 기법을 사용한 경우에도 벤치마크 알고리즘의 예측 정확도에는 큰 변화가 없는 것으로 평가되었다. 전이학습의 잠재적인 활용 방안으로는 데이터 부족으로 인해 심증학습 기반의 신규 예측 모델 개발이 어려운 타겟 도메인에 (소스 도메인에서 개발된) 기존 모델의 신속한 재사용이 포함될 수 있을 것으로 판단된다.
주제어: 전이학습, 심층학습, 합성곱 신경망, 장단기 메모리, 폐수처리공정
1. 서 론
현대 도시 운영에 필요한 물 인프라 중 하나인 폐수처리시설은 공중 보건을 유지하고 인근 하천으로 방류되는 다양한 유해 화학물질을 정화하여 환경 및 수자원 보존을 위해 중요한 역할을 하고 있다[ 1]. 폐수처리시설의 방류수는 물환경보전법 시행규칙 제26조에 따라 엄격한 수질관리가 이루어지고 있으며, 특히 수질원격감시체계(Tele-Monitoring System)를 통해 수질오염물질의 배출상태에 대한 상시 모니터링이 수행되고 있다[ 2]. 참고로, 현재 국내에는 2023년 기준으로 전국에서 56,430개소의 폐수처리시설이 운영 되어 매일 5,006톤의 폐수를 방류 중에 있다. 한편, 폐수처리시설의 방류수에서 수집되는 실시간 모니터링 데이터는 방류수질기준 초과에 따른 배출부과금의 산정 목적 이외에 향후 스마트 폐수처리 시스템 개발, 디지털 기반 물관리 분야 등에 다양하게 활용될 수 있을 것으로 기대되고 있다[ 3, 4]. 최근 상수 및 하폐수 처리공정을 모사하기 위해 인공지능(기계학습 및 심층학습) 기반 알고리즘 적용이 증가하고 있으며[ 5, 6], 이는 기존 지배방정식 기반의 모델에 비해 모델 예측에 필요한 입력 데이터 및 시간 소요가 적고 정확성이 다소 우수한 장점이 있기 때문이다. Li 등[ 7] 및 Jiang 등[ 8]은 시계열 데이터의 (고차원) 시간 종속적인 패턴을 효과적으로 해석할 수 있는 순환신경망(Recurrent neural network, RNN)을 활용하여 상수 처리 공정을 우수한 성능으로 모사하는 방법을 개발하였다. Fahri 등[ 9]은 장단기 메모리(Long short-term memory, LSTM) 알고리즘을 이용하여 하폐수 처리공정을 모사하는 방법을 개발하여 모델의 예측 성능은 최소 90% 이상의 정확도를 가지는 것으로 평가되었다. 이 외에도 상수 및 하폐수 처리 공정을 모사하기 위하여 양방향 LSTM(Bidirectional LSTM, Bi-LSTM), 어텐션 매커니즘(Attention mchanism), 합성곱 신경망(Convolutional neural network, CNN) 등을 활용한 하이브리드 모델들을 이용하여 기존의 인공지능 기반 예측 모델의 성능을 보다 향상한 연구들이 다양하게 제시된 바 있다[ 10, 11, 12]. 다만, 이러한 인공지능 기반 예측 모델은 기존 공정이 아닌 신규 공정에서의 예측 성능은 크게 저하될 수 있을 것으로 예측되고 있다. 전이학습은 기존 시스템(소스 도메인)에서 개발된 인공지능 기반 예측 모델을 신규 시스템(타겟 도메인)에 추가적인 모델 개발 없이 즉각적으로 사용하는 기술로서, 예측 모델 개발에 필요한 시간과 노력을 단축할 수 있는 장점이 있다[ 13]. 또한, 전이학습 기법은 신규 시스템에서 모델 예측에 필요한 충분한 데이터가 부재할 때에도 활용될 수 있으며, 즉 데이터가 풍부한 기존 시스템에서 모델을 개발한 이후 신규 시스템에서 미세 조정(입력, 은닉 및 출력 레이어 고정 또는 변경 등)을 통해 예측 정확도를 개선할 수 있다[ 14]. 다만, 전이학습을 적용을 위해서는 기존 및 신규 시스템이 유사하다는 전제조건이 요구된다. 전이학습의 대표적인 적용 사례로, Lv 등[ 15]은 도시 지역에서 학습한 모델을 이용하여 시골 지역의 대기질을 예측하였으며, Ma 등[ 16]은 기존 관측소를 기반으로 훈련한 Bi-LSTM 모델을 새 관측소에서 대기질 예측 연구에 적용하였다. 또한, 전이학습은 최근 교통 흐름 예측 및 국가 환율 예측의 데이터 부족 문제를 해결하는 연구 등에도 적용된 바 있다[ 17]. 한편, 전이학습의 이러한 우수한 확장성에도 불구하고 현재까지 폐수처리공정에 전이학습을 직접적으로 적용한 국내외 사례는 매우 제한적인 것으로 판단된다. 따라서, 본 연구는 시스템 특성이 매우 유사한 2개의 폐수처리공정(진주시 및 청주시)에서 전이학습의 적용 가능성을 평가하고자 수행되었다. 보다 구체적으로는 본 연구에서는 1) 폐수처리공정의 유량 및 수질 예측을 위해 2개 심층학습 알고리즘의 성능을 우선적으로 평가하고, 전이학습 적용 시나리오 변화 즉, 2) 기존 은닉층 전체 사용 및 3) 부분 사용에 따른 전이학습 기법의 성능 변화를 비교, 분석하였다. 본 연구는 향후 학습 데이터(저해상도 모니터링 자료 등)의 제약으로 인해 인공지능 기반 예측 모델 개발이 직접적으로 어려운 시스템에 유용하게 활용될 수 있을 것으로 기대된다.
2. 실험 방법
2.1. 폐수처리공정 선정 및 입력 데이터 구축
본 연구에서는 전이학습 적용을 위해 시스템 구성이 동일한 2개의 폐수처리공정(진주시 상평산업단지에 위치한 폐수종말처리장 및 청주시 국가산업단지에 위치한 폐수종말처리장)을 선정하였다. 참고로, 2개의 폐수처리공정은 모두 1차 침전공정과 2차 생물학적 처리공정으로 구성되어 있다. 본 연구에서는 2개의 폐수처리공정의 유출수로부터 측정되는 최근 5년간(2018년 1월 1일 ~ 2022년 12월 31일)의 모니터링 데이터를 심층학습 및 전이학습 모델의 입력 자료로 사용하였다( Tables 1 및 2). 모니터링 데이터는 총 9개의 항목으로 구성되어 있으며, (전이학습의 적용성을 시범적으로 평가하기 위한) 예측을 위한 변수로 유량(Discharge)과 생물화학적 산소 요구량(Biochemical oxygen demand, BOD)을 선정하였다. 모니터링 데이터 내 결측값(Missing value)이 부분적으로 발생함에 따라 특정 항목에 결측값이 발생한 경우 보간 없이 모든 데이터를 제외하여 평가를 수행하였으며, 이상치(Outlier)의 경우 사분범위(Interquartile range, IQR)의3배 범위를 이용하여 특정 항목에 이상치가 발생한 경우 결측값과 동일하게 모든 데이터를 제외하여 평가를 수행하였다. 그 결과 진주시 및 청주시 폐수종말처리장에서 총 1,139 및 1,121의 데이터가 각각 사용되었다.
2.2. 벤치마크 알고리즘
본 연구에서는 전이학습을 적용을 위한 심층학습 기반의 벤치마크 알고리즘으로 연구자들에게 활용도가 높은 (비시계열 기반) 합성곱 신경망(CNN)과 (시계열 기반) 장단기 메모리(LSTM)를 사용하였다. 합성곱 신경망(CNN)은 하나 또는 여러 개의 합성곱 계층(Convolutional layer)과 통합 계층(Pooling layer), 그리고 완전하게 연결된 계층(Fully connected layer)으로 구성되어 있다. 합성곱 신경망(CNN)의 주요 장점으로는 다른 비시계열 기반 유사 심층학습 알고리즘에 비해 파라미터 가중치 공유를 통한 학습 파라미터의 개수를 감소시켜 효율적인 학습 속도를 제공하는 장점이 있다. 한편, 장단기 메모리(LSTM)는 은닉층의 메모리 셀에 입력 층, 망각 층, 출력 층으로 구성된 알고리즘으로서, 기존의 시계열 모델인 순환신경망(RNN)의 (학습과 예측 시점 간의 차이가 커짐에 따라 학습 능력 저하의) 단점을 극복하기 위해 제안된 알고리즘으로 알려져 있다. 장단기 메모리(LSTM)의 주요 장점으로는 다른 시 계열 기반 유사 알고리즘에 비하여 비교적 긴 시퀀스의 입력을 처리하는 데에 유용한 것으로 알려져 있으며, 특히 데이터의 크기가 클수록 보다 정확한 예측 성능을 나타내는 것으로 평가되고 있다. 본 연구에서는 다양한 전이학습 적용(은닉층 레이어 전체 사용 및 부분 사용)에 따른 벤치마크 심층학습 알고리즘의 성능 변화를 평가하기 위하여 2개 알고리즘에 단일 은닉층이 아닌 다중 은닉층을 사용하였다. 즉, 합성곱 신경망(CNN)의 경우 4개의 은닉층을, 장단기 메모리(LSTM)의 경우 3개의 은닉층을 각각 사용하였으며, (시범 연구로서 심층학습과 전이학습의 단순한 성능을 비교하기 위하여) 별도의 초매개변수 최적화는 수행하지 않았다. 본 연구에서 사용한 보다 자세한 2개 심층학습의 알고리즘 구조는 Fig. 1에 제시되어 있다.
2.3 전이학습
전이학습은 우선 1) 구축된 모델의 활용 측면 또는 2) 데이터의 크기 및 유사성 측면에 따라 적용 방법을 달리 할 수 있다. 본 연구에서는 2개 폐수처리공정의 데이터의 크기 및 유사성을 평가하기 위한 명확한 판단 기준이 부재하여 구축된 모델의 활용 측면을 단순히 고려하여 평가에 활용하였다. 구축된 모델의 활용 측면에서 전이학습은 다음과 같은 3가지 방식이 주로 적용되고 있다. 즉, 기존 은닉층 전부를 사용하고 출력층만 훈련하는 경우(Case A), 기존 은닉층을 일부를 사용하고 나머지 은닉층을 훈련하는 경우(Case B), 모델의 구조(기존 은닉층 및 출력층 모두 훈련)만 활용하는 경우(Case C)로 구분할 수 있다. 본 연구에서는 폐수처리공정에 전이학습의 적용성을 시범적으로 평가하기 위하여 단순히 Case A(3.2 섹션)와 Case B(3.3 섹션)를 사용하여 성능 변화를 분석하였다. 참고로, 전이학습 방식 중 Case B의 경우 기존 모델의 다양한 은닉층 중 말단의 최종 은닉층(레이어)만을 훈련에 사용하였다. 또한, 전이학습을 통해 청주시 폐수처리공정의 유량 및 수질을 예측하는 경우 진주시 폐수처리공정에서 개발한 유량 및 수질 예측 모델을 활용하였으며, 전이학습을 통해 진주시 폐수처리공정의 유량 및 수질을 예측하는 경우 정반대의 방향으로 예측 모델들을 활용하였다.
2.4. 모델 개발 및 평가 환경
심층학습 및 전이학습은 모두 파이썬(Python, Version 3.7.9) 환경에서 범용성이 뛰어난 케라스(Keras, Version 2.4.3) 패키지를 사용하다. 심층학습 및 전이학습의 입력 데이터는 최소값 및 최대값을 통해 정규화(Min-max scaling) 되었으며, 손실 함수의 최적화 함수로 RMSProp과 성능 평가 지표로 평균제곱오차(Mean squared error, MSE)를 각각 사용하였다. 본 연구에서 훈련 및 테스트 데이터는 7:3의 비율로 구분하여 평가를 수행하였으나, 단순화된 평가 결과를 제시하기 위하여 테스트 결과만을 제시하였다.
3. 결과 및 고찰
3.1. 심층학습 알고리즘 성능
Table 3은 진주시 및 청주시 폐수처리공정에서의 2개 벤치마크 심층학습 알고리즘에 대한 유량 및 생물화학적 산소요구량의 예측 성능을 나타내고 있다. 우선, 진주시 폐수처리공정의 유량을 예측하는 경우 평균제곱오차(MSE)를 기준으로 장단기 메모리(LSTM)의 예측 성능이 합성곱 신경망(CNN)에 비해 우수한 것으로 조사되었으며, 이와는 반대로 청주시 폐수처리공정의 유량 예측 시 합성곱 신경망(CNN)의 장단기 메모리(LSTM)에 비해 성능이 보다 우수한 것으로 평가되었다. 또한, 진주시 및 청주시 폐수처리공정의 생물화학적 산소요구량을 예측하는 경우 각각 장단기 메모리(LSTM) 및 합성곱 신경망(CNN)이 상대적으로 우수하여, 유량 예측과 동일한 성능 우선순위가 도출되었다. 다만, 진주시 및 청주시 폐수처리 공정 모두 유량의 예측 성능이 생물화학적 산소요구량에 비해 보다 우수한 것으로 조사되었으며, 이러한 원인은 폐수처리공정 유출수에서 유량의 변동성(변동 계수=표준 편차/평균, 진주시 7.90, 청주시 32.38)이 생물화학적 산소요구량의 변동성(진주시 16.86, 청주시 55.55)에 비해 상대적으로 낮기 때문인 것으로 판단된다.
3.2 전이학습 알고리즘 성능
Fig. 2는 진주시 및 청주시 폐수처리공정에서의 전이학습 적용 전과 후의 a) 유량 및 b) 생물화학적 산소요구량의 예측 성능을 비교하고 있다. 평가 결과, 유량 예측 시 전이학습을 적용할 경우 평균제곱오차(MSE)를 기준으로 적용된 벤치마크 알고리즘에 관계없이 예측 성능이 모두 향상되는 것으로 조사되었다. 다만, 유량 예측 시 장단기 메모리(LSTM)의 경우 전이학습 적용에 따른 예측 성능 개선 정도는 기존 공정(소스 도메인)에서 신규 공정(타겟 도메인)으로의 적용 방향(진주시 → 청주시 vs 청주시 → 진주시)에 따라 큰 차이가 발생하는 것으로 조사되었다. 한편, 생물화학적 산소요구량 예측 시 전이학습을 적용할 경우 합성곱 신경망(CNN)에 한하여 예측 성능이 유지되거나 개선되었으며, 장단기 메모리(LSTM)의 경우 오히려 예측 성능이 감소하는 것으로 조사되었다. 다만, 예측 변수에 관계없이 전이학습 적용 전과 후의 예측 성능이 크게 상이하지 않아 동일하거나 유사한 폐수처리공정에서 전이학습 기법의 적용 가능성은 다소 높은 것으로 평가되었다.
3.3. 전이학습 적용 방법 변화에 따른 성능
Table 4는 진주시 및 청주시 폐수처리공정에서의 전이학습 적용 방법 변화(기존 은닉층 전체 사용(Case A) 및 부분 사용(Case B))에 따른 유량 및 생물화학적 산소요구량의 예측 성능을 비교하고 있다. 진주시 및 청주시 폐수처리공정에서 유량 예측의 경우 평균제곱오차(MSE)를 기준으로 전이학습 적용 방법 변화에 따른 (적용된 벤치마크 알고리즘에 관계없이) 예측 성능에 큰 차이가 없는 것으로 조사되었다. 다만, 청주시 폐수처리공정에서 유량 예측 시 장단기 메모리(LSTM)의 경우 전이학습 적용 방법 변화(Case A → Case B)에 따라 예측 성능이 소폭 감소하는 것으로 평가되었다. 또한, 생물화학적 산소요구량 예측 시에도 진주시 및 청주시 폐수처리공정에서 모두 전이학습 적용 방법 변화에 따른 (적용된 벤치마크 알고리즘에 관계없이) 예측 성능에 큰 차이가 없는 것으로 조사되었다. 따라서, 향후 전이학습 적용 방법에 따른 예측 성능의 보다 구체적인 조사가 필요할 것으로 판단되지만, 본 연구 결과는 폐수처리공정에서 전이학습 기법의 적용 가능성을 뒷받침하는 중요한 기초자료로 활용될 수 있을 것으로 판단된다.
4. 결 론
본 연구에서는 폐수처리공정에서 전이학습 기법의 적용 가능성을 평가하고자 수행되었다. 전이학습 적용을 위한 벤치마크 알고리즘으로는 비시계열(합성곱 신경망, CNN) 및 시계열 기반 알고리즘(장단기 메모리, LSTM)을 사용하였으며, 벤치마크 시스템으로는 동일한 처리공정으로 구성된 2개(진주시 및 청주시)의 폐수처리공정을 선정하였다. 2개 폐수처리공정의 유출수로부터 총 5년(2018년 1월 ~ 2022년 12월) 기간의 모니터링 자료를 모델의 입력 자료로 사용하였으며, 벤치마크 알고리즘 대비 전이학습 적용 전후(기존 은닉층 전체 사용 유무) 및 방법 변화(기존 은닉층 전체 vs 부분 사용)에 따른 성능 변화를 평가하였다. 본 연구를 통해 도출된 주요 연구결과는 다음과 같다.
• 합성곱 신경망(CNN) 및 장단기 메모리(LSTM)의 성능은 예측 항목(유량 vs 생물화학적 산소요구량) 및 폐수처리공정(진주시 vs 청주시)에 따라 소폭 상이하였으나 대체로 유사한 것으로 조사되었다. 다만, 생물화학적 산소요구량 대비 유량의 변동성이 낮아 (적용 알고리즘에 관계없이) 유량에 대한 예측 성능이 보다 우수한 것으로 조사 되었다.
• 2개의 벤치마크 알고리즘에 전이학습(기존 은닉층 전체 사용 유무)을 적용한 결과 유량 예측 시 예측 성능이 개선되는 것으로 조사되었으며, 생물화학적 산소요구량 예측 시 예측 성능이 유지되거나 소폭 감소하는 것으로 평가되었다. 이를 통해 동일하거나 유사한 폐수처리공정에서(모델 적용 방향에 관계없이) 전이학습의 적용 가능성은 다소 높은 것으로 평가되었다.
• 전이학습 기법의 적용 방법 변화(기존 은닉층 전체 vs 부분 사용)에 따른 성능 변화를 평가한 결과 전이학습의 예측 성능에는 큰 변화가 없는 것으로 평가되었다. 다만, 1) 데이터의 크기 및 유사성에 기반한 상이한 전이학습 기법의 적용과 2) 대상 시스템(공정), 벤치마크 알고리즘, 예측 항목 및 초매개변수 최적화 등에 따라 벤치마크 알고리즘의 예측 성능이 다양하게 변화할 수 있을 것으로 예측됨에 따라 향후 전이학습에 대한 심도 있는 후속 연구가 지속적으로 수행될 필요가 있을 것으로 판단된다.
Acknowledgments
본 논문은 농촌진흥청 연구사업(세부과제번호: PJ015845)의 지원에 의해 이루어진 것임.
Notes
Declaration of Competing Interest
The authors declare that they have no known competing interests or personal relationships that could have appeared to influence the work reported in this paper.
Fig. 1.
Model structure of two benchmark deep learning algorithms adopted in this study: (a) CNN and (b) LSTM. 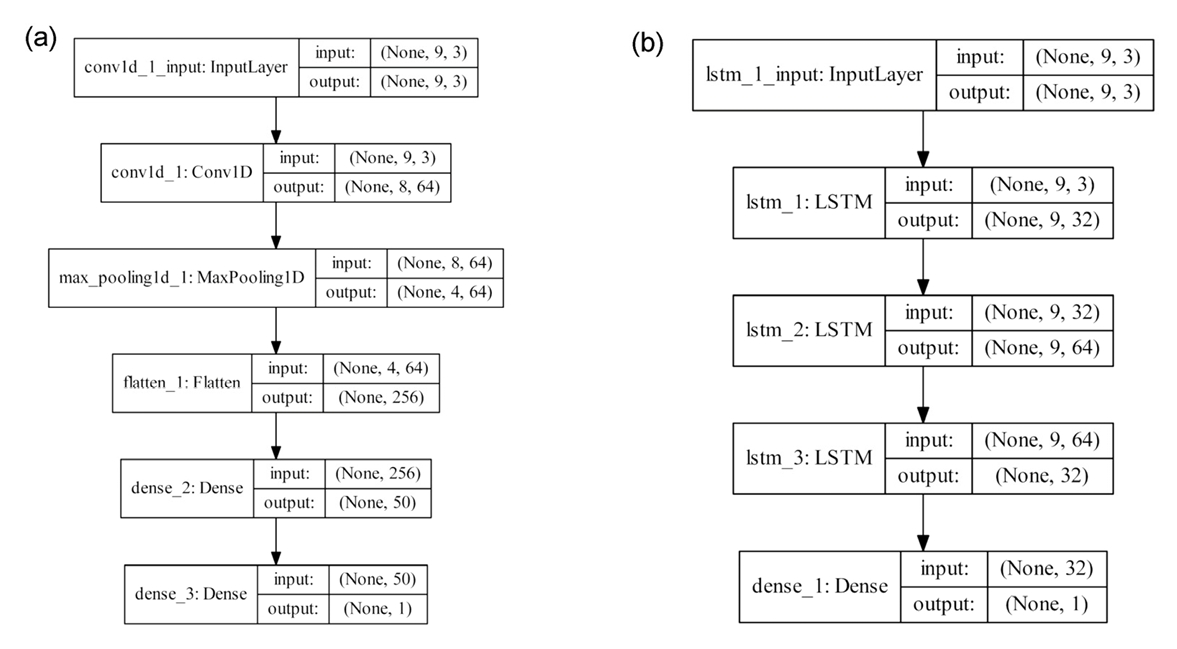
Fig. 2.
The prediction accuracy of two benchmark algorithms (CNN and LSTM) with and without transfer learning for two dependent variables (discharge and BOD) in terms of MSE. Note that JJ and CJ indicate the wastewater treatment plants in Jinju and Cheongju, respectively. 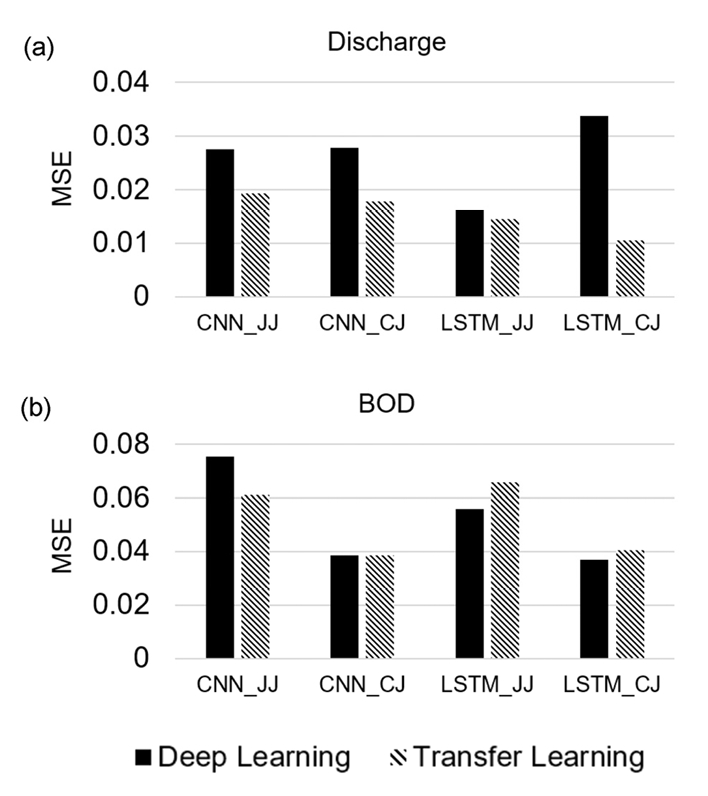
Table 1.
Summary statistics for 9 effluent quality parameters observed on a daily basis between 2018 and 2022 at wastewater treatment plant in Jinju City.
|
Input variablesa)
|
n
|
Missing data |
Mean |
Standard deviation |
p0 |
p25 |
p50 |
p75 |
p100 |
|
Discharge |
1,252 |
0 |
21,190 |
1,675 |
11,544 |
20,229 |
21,226 |
22,294 |
25,930 |
|
W-temp |
1,252 |
0 |
23.9 |
5.26 |
13.2 |
19.7 |
23.8 |
28.4 |
36.6 |
|
pH |
1,252 |
0 |
7.18 |
0.184 |
6.5 |
7 |
7.2 |
7.3 |
7.8 |
|
BOD |
1,252 |
0 |
1.93 |
0.625 |
0.5 |
1.4 |
2 |
2.4 |
3.9 |
|
COD |
1,252 |
0 |
13 |
2.46 |
3.5 |
11.3 |
13.2 |
14.8 |
19 |
|
SS |
1,252 |
0 |
2.07 |
0.971 |
0.2 |
1.4 |
2 |
2.6 |
6.6 |
|
T-N |
1,252 |
0 |
8.72 |
2.68 |
2.1 |
6.85 |
8.49 |
10.5 |
19.9 |
|
T-P |
1,252 |
0 |
0.0685 |
0.0306 |
0.01 |
0.047 |
0.067 |
0.088 |
0.266 |
|
TC |
1,252 |
18 |
16.1 |
19.7 |
0 |
5 |
8 |
20 |
170 |
Table 2.
Summary statistics for 9 effluent quality parameters observed on a daily basis between 2018 and 2022 at wastewater treatment plant in Cheongju City.
|
Input variables |
n
|
Missing data |
Mean |
Standard deviation |
p0 |
p25 |
p50 |
p75 |
p100 |
|
Discharge |
1,256 |
0 |
21,661 |
3,652 |
9,636 |
18,871 |
20,866 |
24,848 |
36,374 |
|
W-temp |
1,256 |
0 |
23.6 |
4.96 |
7 |
19.6 |
23.8 |
28.1 |
32.8 |
|
pH |
1,256 |
0 |
6.85 |
0.383 |
6.1 |
6.6 |
6.8 |
7 |
16 |
|
BOD |
1,256 |
0 |
2.79 |
1.55 |
0.1 |
1.6 |
2.5 |
3.9 |
8.6 |
|
COD |
1,256 |
0 |
11.2 |
3.18 |
4.3 |
8.3 |
11.4 |
13.7 |
19.2 |
|
SS |
1,256 |
0 |
3.13 |
0.822 |
0.8 |
2.7 |
3.1 |
3.5 |
7.6 |
|
T-N |
1,256 |
0 |
10.5 |
5.35 |
1.36 |
7.07 |
9.15 |
11.9 |
32.3 |
|
T-P |
1,256 |
0 |
0.0696 |
0.0366 |
0.01 |
0.044 |
0.061 |
0.085 |
0.246 |
|
TC |
1,256 |
0 |
351 |
314 |
31 |
200 |
240 |
330 |
2,100 |
Table 3.
The prediction accuracy of two benchmark deep learning algorithms (CNN and LSTM) for two dependent variables (discharge and BOD) in terms of MSE.
|
Wastewater treatment plants |
Discharge
|
BOD
|
|
CNN |
LSTM |
CNN |
LSTM |
|
Jinju |
0.0276 |
0.0162 |
0.0754 |
0.0559 |
|
Cheongju |
0.0278 |
0.0337 |
0.0366 |
0.0371 |
Table 4.
The prediction accuracy of two benchmark algorithms (CNN and LSTM) with two different transfer learning approaches (Cases A and B) for two dependent variables (discharge and BOD) in terms of MSE.
|
Wastewater treatment plants |
Transfer learning approaches |
Discharge
|
BOD
|
|
CNN |
LSTM |
CNN |
LSTM |
|
Jinju |
Case A |
0.0133 |
0.0146 |
0.0168 |
0.0195 |
|
Case B |
0.0137 |
0.0145 |
0.0168 |
0.0205 |
|
Cheongju |
Case A |
0.0132 |
0.0151 |
0.0212 |
0.0245 |
|
Case B |
0.0131 |
0.0195 |
0.0211 |
0.0240 |
References
1. A. Marin-Ramirez, T. Mahoney, T. Smith, R. H. Holm, Predicting wastewater treatment plant influent in mixed, separate, and combined sewers using nearby surface water discharge for better wastewater-based epidemiology sampling design, Science of The Total Environment., 906, 167375(2024).  2. K. H.. Park, B. J.. Kang, J. C.. Kim, I. H.. Choi, Feasibility Study on Statistical Consideration of Effluent Quality Limits in Sewage Treatment Plants, Journal of Korean Society of Water and Wastewater., 24(3), 253-264(2010).
3. A. L.. Karn, S.. Pandya, A.. Mehbodniya, F.. Arslan, D. K.. Sharma, K.. Phasinam, ..., S.. Sengan, An integrated approach for sustainable development of wastewater treatment and management system using IoT in smart cities, Soft Computing., 27, 5159-5175(2023).  4. W.. Liu, S.. He, J.. Mou, T.. Xue, H.. Chen, W.. Xiong, Digital twins-based process monitoring for wastewater treatment processes, Reliability Engineering & System Safety., 238, 109416(2023). 5. J.. Yu, Y.. Tian, H.. Jing, T.. Sun, X.. Wang, C. B.. Andrews, C.. Zheng, Predicting regional wastewater treatment plant discharges using machine learning and population migration big data, ACS ES&T Water., 3(5), 1314-1328(2023). 6. F.-J.. Chang, L.-s.. Kao, Y.-M.. Kuo, C.-W.. Liu, Artificial neural networks for estimating regional arsenic concentrations in a blackfoot disease area in taiwan, Journal of hydrology., 388(1-2), 65-76(2010). 7. L.. Li, P.. Jiang, H.. Xu, G.. Lin, D.. Guo, H.. Wu, Water quality prediction based on recurrent neural network and improved evidence theory: a case study of qiantang river, china, Environmental Science and Pollution Research., 26(19), 19879-19896(2019). 8. Y.. Jiang, C.. Li, Y.. Zhang, R.. Zhao, K.. Yan, W.. Wang, Data-driven method based on deep learning algorithm for detecting fat, oil, and grease (fog) of sewer networks in urban commercial areas, Water Research., 207, 117797(2021). 9. N.. Farhi, E.. Kohen, H.. Mamane, Y.. Shavitt, Prediction of wastewater treatment quality using LSTM neural network, Environmental Technology & Innovation., 23, 101632(2021). 10. Q.. Zou, Q.. Xiong, Q.. Li, H.. Yi, Y.. Yu, C.. Wu, A water quality prediction method based on the multi-time scale bidirectional long short-term memory network, Environmental Science and Pollution Research., 27(14), 16853-16864(2020). 11. Y.. Yu, X.. Si, C.. Hu, J.. Zhang, A review of recurrent neural networks: lstm cells and network architectures, Neural Computation., 37(7), 1235-1270(2019). 12. Y.. Yang, Q.. Xiong, C.. Wu, Q.. Zou, Y.. Yu, H.. Yi, M.. Gao, A study on water quality prediction by a hybrid CNN-LSTM model with attention mechanism, Environmental Science and Pollution Research., 28(39), 55129-55139(2021). 13. S.. Minami, S.. Liu, S.. Wu, K.. Fukumizu, R.. Yoshida, A general class of transfer learning regression without implementation cost, In Proceedings of the AAAI Conference on Artificial Intelligence., 35(10), 8992-8999(2021). 14. K.. Weiss, T. M.. Khoshgoftaar, D.. Wang, A survey of transfer learning, Journal of Big data., 3, 1-40(2016). 15. M.. Lv, Y.. Li, L.. Chen, T.. Chen, Air quality estimation by exploiting terrain features and multi-view transfer semi-supervised regression, Information Sciences., 483, 82-95(2019). 16. J.. Ma, Z.. Li, J. C.. Cheng, Y.. Ding, C.. Lin, Z.. Xu, Air quality prediction at new stations using spatially transferred bi-directional long short-term memory network, Science of The Total Environment., 705, 135771(2020). 17. R.. Ye, Q.. Dai, A relationship-aligned transfer learning algorithm for time series forecasting, Information Sciences., 593, 17-34(2022).
|
|










